[PART 1] The current and future state of AI from Kazakhstan's perspective: From programming languages to a natural language interface.
DISCLAIMER: I used LLMs only for partial translation from Russian to English and for editing grammatical mistakes in this text. I welcome your feedback and further discussions.
Introduction
I want to share my perspective as a citizen of Kazakhstan on current regional and global AI-related (artificial intelligence) trends with potential security risks. As communities and society transition into a new agentic era affecting all spheres of life, science fiction becomes a reality similar to the Tron movie series in Figure 1, where everyone has a digital reflection or a sentient bot within computer simulations.
For example, Jensen Huang (the founder and CEO of Nvidia) stated at GTC Taipei 2026 that there will be more AI agents than humans, with each of us having a multitude of such assistants performing our daily tasks and work. Anyone can now become a digital creator, producing prototypes and expressing ideas via a natural language interface without deep technical skills. On the other hand, this trend toward the widespread integration of AI agents, especially into critical infrastructure, can increase security risks and attack surfaces. Moreover, experts from MIT have shown that overreliance on these systems might lower certain literacy skills, but it remains unclear and further studies are needed to determine how outsourcing for problem-solving and overreliance on such systems affect our potential long-term cognitive degradation. Also, the current market condition widens the inequality gap due to a heavy dependency on large frontier model providers (e.g., Google, OpenAI, Antropic, xAI/SpaceX, Meta, and others). According to news reports and leaked documents, Microsoft attempts to push AI tools into workflows and related services used by knowledge workers and non-technical specialists in order to make them “more dependent” on its ecosystem of products (e.g., Azure, Windows, Office 365, and GitHub). Therefore, I stand by the position that Kazakhstan and independent nations should systematically shift toward local alternatives and evaluate their feasibility due to the factor of problematic pricing. This should be a natural evolution with structured planning and community-driven actions, rather than top-down directives or one-off cases.
I decided to split my initial post into two parts due to being stuck in development hell. In this first part, I’ll discuss about vibe coding, natural language programming, and the hype about AI. The second part will cover AI security, agentic systems, and concepts of decentralized AI.
Hype about AI
AI is a field of study and research, not a single solution. There are subfields and approaches to AI, which are well-described in “the history of AI” section of the Stanford CS221 course. For example, any regular software can be classified as a type of symbolic AI, including rule-based and formal logical systems. Usually, public rhetoric from government agencies and corporations about integrating AI into existing or new systems fails to reflect reality. They tend to blur everything under an abstract and universal “AI” while implicitly referring to data-driven AI (statistical and neural models) and a combination of other AI approaches. I think it should be mentioned explicitly about technical details and actual engineering behind the scenes: methodologies, limitations, solutions, frameworks, problems, domains, architectures, techniques (e.g., natural language processing, computer vision, machine learning, deep learning, generative models, transformers, and so on).
Kazakhstan’s social media highlights “Higgsfield AI” as our innovation and breakthrough in AI, but it primarily operates in the entertainment sector, allowing only to produce generative videos and images. However, when it comes to other use cases (e.g., finances, logistics, marketing), it becomes clear that not all AI applications and solutions are comparable, so instead we should differentiate them as a detailed AI landscape, as shown in Figure 2.
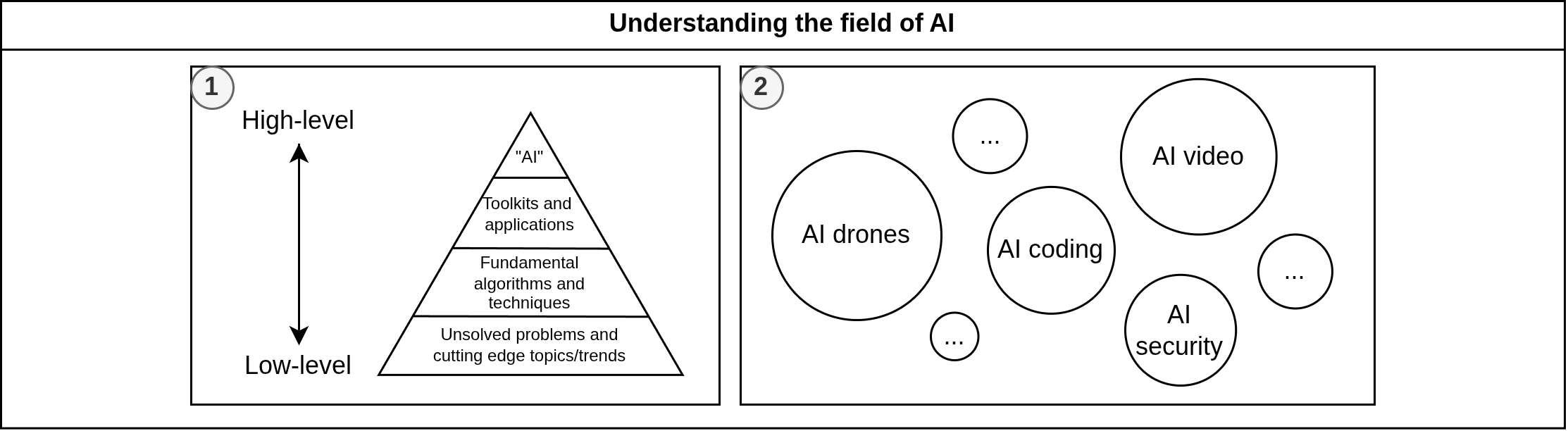
The lack of such introspection principles to analyze and understand the field leads to industry decline under the pressure of black-box system vendors. They claim to have “perfect systems” that can solve “every possible problem”, resulting in overall stagnation around a single approach instead of driving innovative research - same pattern has historically led to multiple series of AI winters. Furthermore, AI psychosis, as a combination of fear of missing out and hype among non-technical specialists, propagates misconceptions and misleading narratives to the general public. For example, Bagdat Musin (former minister of digital development of Kazakhstan) claims in his recent interview that will be layoffs and hiring restrictions for those who do not practice “vibe coding”, and he predicts that management positions will replace technical specialists via AI agents. He also mentioned that he had not done any programming session since 2005 and had been developing for a maximum of 3-4 years during his university time, so we shouldn’t trust or listen to him as a credible source of truth due to a complete lack of actual technical understanding and proficiency. Similar individuals insist that “the AI train is leaving and we are getting left behind in the race if we don't embrace it”, but it is more reasonable to think in the long term like “the train has always been moving, we have always been a part of it, and it only depends on us where we will sit inside it”:
“the train has always been moving” - constant scientific and technological progress;
“we have always been a part of it” - our integration into the global economy;
“our seating position/place” - unique specialization as a country and a nation.
Intermediary systems for translating our intentions
Reading this part is necessary in order to understand distinctions and similarities between computer/programming languages and natural language.
Historically, the IT industry has built layers of abstraction to make software development process faster and more human-oriented: machine code → assemblers → high-level programming languages (PL) → no-code platforms (visual canvas and node graphs). We write programs as a set of instructions, expressing and modeling logical constructs (e.g., problems, solutions, algorithms, data structures, ideas, intentions, and assumptions), that are executed by a computer. For example, a program in the C language is only a formal instruction for a specific compiler. In this case, such a compiler acts as an intermediary system which we trust and delegate responsibility to in an attempt to produce an executable binary from the source code, following the PL specification and its supported features, as demonstrated in Figure 3.
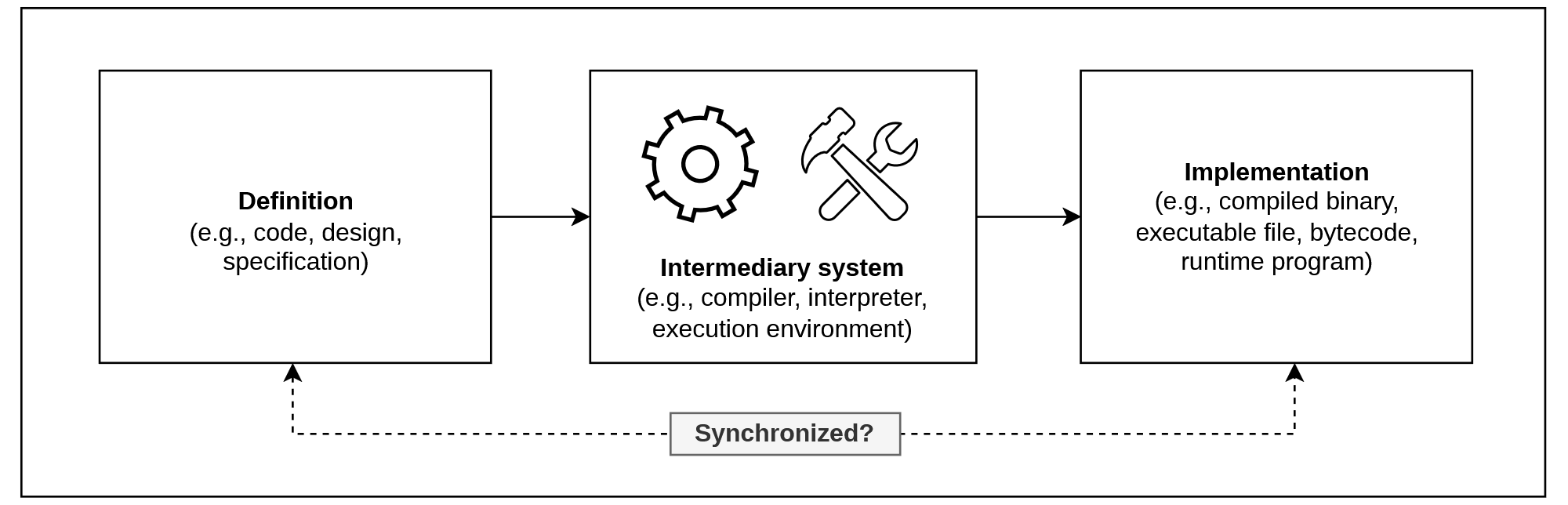
However, we cannot be truly sure that these systems preserve the exact same semantics, so it may prevent software from working “correctly” or as intended (e.g., OS and hardware integration flaws, unexpected errors, non-deterministic behavior, internal compiler errors, and injection of malicious code or backdoors). It is possible to inspect generated artifacts via the formal process of “reverse engineering”, which requires additional efforts due to applied manipulations (optimizations, obfuscation, stripped debug parts, and anti-analysis techniques), the need for professional skills in reviewing low-level code, specialized analysis tools, and many other factors. Nowadays, the ecosystem of compilers is centralized around a limited number of “universal compilers” like LLVM and GCC, where potential transformation issues can occur at any stage due to multiple reasons:
High-level PL consists of a set of non-native instructions that have an execution model like an abstract machine (i.e., the C++ abstract machine). These “front-ends” have formalized notations and different parsing approaches (e.g., Backus-Naur Form, regular expressions, lex/yacc, and so on) in order to translate the source code into an intermediate representation (IR) in various forms (e.g., native machine code, intermediate languages, abstract syntax trees, bytecode for a virtual machine). From such perspective, PL limits us within a constrained space (syntax, semantics, Turing completeness, and idiomatic requirements). For example, loops and structs didn’t exist in Fortran (it is still alive and not dead PL), where they instead used “goto” operations based on jumps and arrays respectively, so structured programming tried to introduce more higher-level constructs in modern PLs to prevent that. Of course, this is a superficial description on the topic from my perspective, so you can take a course on compilers and interpreters on your own, such as CS6120 from Cornell and others.
Any programming language is just a tool that depends on an user, just like a gun which can be a weapon used to kill others or oneself (both in defense and attack purposes). On the one hand, there are PLs that lack certain guarantees and regulations at compile time and run time, leading to non-reproducible bugs (e.g., reading garbage from memory, memory violations with program crashes, and logical errors) and unexpected behavior (e.g., undefined behavior, implementation-defined behavior, erroneous behavior, unspecified behavior, etc.). On the other hand, there is a specific category of PLs that focuses on setting restrictions and guardrails on coding style like separating safe and unsafe sections.
Portability is ensured by the middle-end (IR processing and manipulation) and back-end (translation of IR to native machine code/instructions on the target) components of the compiler. However, aggressive code optimization within the IR (such as applying the -O3 flag) can rewrite the program's structure along with its semantics, leading to flaky bugs or distort our original intentions and putting end users at risk. We have incomplete control over the compiler, because it might ignore our “notes” (directives and attributes) and compilation parameters (specified in console or config files).
Many PLs suffer from inconsistencies and inconveniences that either accumulated historically over time or were fundamentally flawed by design, because their authors were constrained by hardware limitations and computer science paradigms of the past:
Safety and security. For example, C strings are null terminated (contain a “\0” character at their end), but careless handling of them (forgetting to account for it during size checking and processing) can lead to out of bounds writes, buffer overflow, and other types of vulnerabilities. Modern developers now understand that it is safer to handle like a “string_view” immutable structure, where we only store the string’s length and a pointer to its beginning. Although nothing can be guaranteed to be 100 percent safe or reliable (only 99.9(9) percent in a period is realistic metric) and there is an infinite amount of bugs in any system due to the possibility of errors at different levels of abstraction (even correct program can operate incorrectly due to internal effects like broken/defective hardware or external effects like quantum fluctuations and cosmic rays that flip bits), there is a positive trend toward adopting secure and safety by default/design principles for critical systems:
Memory safety approaches include utilizing modified compilers like Fil-C, runtime checks, garbage collection, and strict memory systems like in Rust. However, they have limited application in low-level cases like the Linux kernel, where Rust developers have to regularly use unsafe blocks to interact directly with hardware in specific memory addresses and common C interface.
Modern PL design mitigates basic flaws like the “billion-dollar mistake” of null references by using None as a sentinel value, handling errors as values through railway-oriented programming, enforcing explicit rather than implicit side effects, defensive programming (overflow handling in compile time, data validation, bounds checking), and contract-oriented programming (post/preconditions and assertions for self-checks in debug and testing).
Introduction of professional tooling: source code analysis, debuggers, profilers, sanitizers, fuzzers, testing, and formal verification.
Features and libraries. Because the standard data types in C do not guarantee fixed sizes due to historical heterogeneity across platforms, it is necessary to use stdint.h or cstdint to ensure predictable type widths. Modern systems PLs (such as Zig, Odin, D, Jai, and C3) don’t have such problems and introduce convenient features, but they are still marginalized with small ecosystems and communities. For instance, Jai provides metaprogramming with reflection (for code generation, typed macros, and type inference) and an integrated build system similar to setuptools. Also, I want to mention Golang, which offers useful features for developing user-space applications and agentic systems:
Structured concurrency and parallelism model, in which it utilizes virtual threads (i.e., goroutines) as an alternative to “colored functions” async APIs for I/O-bound operations (such as web requests, database queries, and non-blocking I/O) and CPU-bound tasks.
Rich standard library includes a built-in HTTP server/client and an SSH client, which are suitable for orchestrating and building localized IaC (Infrastructure as Code) toolkits for running both agent-based and agentless execution across Windows, Linux, and other platforms. It also suitable for distributed systems like blockchain networks or multiplayer games. Moreover, it includes “embed” package to bundle assets (such as .txt files containing default LLM prompts) into a single binary, native PE/ELF readers, etc.
Native compilation to WASM out of the box without requiring external tools like Emscripten compilers or transpilers, allowing it to be seamlessly ported or bundled as part of Android applications and within web browsers.
Additionally, there are numerous issues within libc and its implementations (such as musl, glibc, and libstdc++) related to unsafe or insecure functions and design flaws, which originate from identifier length constraints and adherence to Unix and POSIX standards. C libraries are still widespread due to FFI (foreign function interface) for many PLs and amount of legacy software written in C, but any PL can implement direct syscalls for a specific OS without libc at all.
Implementation vs. standardization. The release cycle for C/C++ standards spans several years, which is a relatively slow process (marking features as deprecated and then waiting for implementing newer ones by compilers) compared to modern PLs that are bound to a single implementation for rapid iteration, but they have to a balance between short-term patching and long-term future-proofing. If changes between releases of standards are too drastic and breaking, libraries struggle to update to new versions and remain stuck on older ones. Linus Torvalds, the creator of the Linux kernel, has already raised the issue that actual implementations of a PL drift from its specification, suggesting they should be only evaluated within the context of a specific compiler (in their case it is GCC).
Management. Committee members present multiple viewpoints on various issues in order to build a collective consensus and democratic efforts. However, it is impossible to satisfy everyone and someone might lobby for certain interests of their organization. Sometimes, BDFL (benevolent dictator for life) representative or their elected alternative can be a temporary measure to maintain a more coherent and consistent view for a PL.
In reality, PLs interact and synergize with each other rather than replacing one another. For example, scripting PLs like Python or Lua act as bindings or wrappers around PLs (e.g., embedding and calling CPython). Alternatively, you can create an interop between PLs to serialize data and bridge interactions directly (e.g., inter-process communications with Py4J and shared memory with JPype between Python and Java). Particularly, Python is popular in the AI era due to its ecosystem of libraries (e.g., for model training, inference, data analysis, and data processing) that utilize compiled PLs under the hood. Personally, I advise being careful when using external packages, because they can expose you to software supply chain attacks, as explained in my previous blog post about the attacks from TeamPCP on package registries. This problem is partly related to language design flaws, such as those Douglas Crockford highlights about JS, where the lack of a robust standard library (i.e., “batteries included” strategy) forces reliance on external dependencies. On the other hand, the state of “broken batteries”, where there are too many weak or unmaintained libraries, might lead to the accumulation of technical debt and possible conflicts around “centralization vs. decentralization”.
Natural language for interacting with computers
Back in 1978, E. W. Dijkstra expressed his opinion about using natural language as a weak abstraction or interface for translating and expressing our intentions to a machine. However, while he was limited by the paradigm of symbolic AI and rule-based systems, other experts of his era were already questioning how software engineering would change in the longer perspective. Some of them introduced the concept of "automatic programming", in which a software developer provides a high-level specification to an AI system that attempts to automatically create an implementation based on it. Nowadays, many ideas of the past are becoming a reality because we can write vague prompts for generative AI (GenAI), such as language models (LMs), to easily perform natural language processing (NLP) operations based on a given input and produce output (e.g., generating scripts in multiple programming languages, text summarization, language translation, sequence to sequence, reasoning or imitation of thinking process, fuzzy matching of data, and operations on multimodal data). So, GenAI now acts as yet another intermediary system that allows us to rise even higher in terms of abstraction.
In this regard, a software project becomes similar to an adaptive organism that evolves or transforms according to specifications provided to LMs. Of course, there have already been toolkits for efficient refactoring and code generation for a long time before GenAI, such as those used for codebase migration (e.g., lib2to3, go fix, langchain-cli migrate), but they require constant maintenance and are quite static:
Suppose an update or a breaking change is released for a project dependency or even new features/specifics in PL.
Run a toolkit that performs operations on the source code to make it compatible with the newer version. Initially, it parses imports, function calls, data structures, and other elements into a some representation. It then attempts to perform operations (e.g., deleting and replacing specific function calls) according to a set of rules and data (e.g., changelogs with predefined key-value "before and after" like in Airflow).
There are complex cases where changes cannot be made automatically, so the system can either notify user to make a manual choice or point out exactly where potential issue is located.
Additionally, there are other common deterministic tools: babel JS transpiler of ES6 constructs into older ES versions for backward compatibility; UV and Django in Python for generating a project from a set of templates; Ruby on Rails annotations and code generators to synchronize distinct components; Alembic/SQLAlchemy database migrations; linters and formatters; and so on. Moreover, LMs are actively being adopted for code editing and source-to-source codebase migrations:
Microsoft conducts research about rewriting Windows OS from C/C++ to Rust;
IBM tries to translate COBOL codebases to Java;
Other overhyped and harmful cases, as joked about in Figure 4.

The next trending approach in the industry became “vibe coding”, which was coined by Andrej Karpathy (co-founder of OpenAI и AI researcher in Antropic) in his post on the Twitter/X platform in 2025. He joked that he preferred to just feel the “vibe” of writing prompts without validating generated output from a coding model. Then, the public turned this meme into an entire pseudo-methodology as a continuation of the “10x engineer” and “move fast and break things” slogans, imagining themselves as genius engineers like in Figure 5. Also, it stems from massive waves of layoffs across big tech companies, which increase overall workload and exploitation of employees, requiring them to vibe code to produce features at high speed while reducing labor costs. Of course, I don’t support anti-AI or neo-Luddite narratives, but rather want to address cases of irresponsible use and rushing, where a specialist does not understand what was produced and cannot properly evaluate quality of the output. I also find it frustrating when unqualified individuals mistake any use of AI systems as “vibe coding”, misleading the public and fostering a negative attitude toward modern AI as a whole.

Accumulation of AI-slop content
However, when we provide ambiguous requirements in prompts or using outdated models, they produce low-quality output from the generation process (i.e., “garbage in, garbage out”), meaning a model tends to generate common patterns from its training data or even an incomplete/distorted form of our intentions (i.e., “AI-slop”), as explained in Figure 5. The same principle applies to LMs generation distribution, where the most common code might be lower quality by:
Containing obsolete coding practices (e.g., memory unsafe code, banned functions, outdated or deprecated features from older versions/specifications).
Having biased solutions (e.g. specific libraries or dependencies, common helper functions, tendency to specific algorithms and data structures, form of writing and styling, adding too much abstraction, abusing/overusing features).
Although Explainable AI principles attempt to address this problem through data and model curation, this extrapolates to a scale of billions and trillions in LLMs (i.e., model weights, parameters, and dataset records), making it increasingly difficult to control. I demonstrated this characteristic in my bachelor’s thesis and recommend checking out Stanford's “Introduction to LLMs” course for a deeper look.
The problem of AI-slopification (production of low-effort synthetic content at a fast speed and in large volumes) accumulates into critical risks (model collapse and hidden errors) due to large-scale automation and absence of human-in-the-loop verification. For example, Microsoft published a study in 2026 on how even latest frontier GenAI models can gradually and partially corrupt delegated work materials (such as documents and other media content), causing distortion of initial details and smoothing out of unique sections. As I understand it, researchers created a simulation with synthetic samples across diverse skills and simulated a file system as well. Their results indicated that files containing code snippets were not subject to significant distortion, demonstrating that certain domains are easier for GenAI models to handle without excessive errors (probably, because of enough training data and restrictiveness of domain). Another study has shown a noticeable increase in noise and visual flaws after multiple iterative passes on the same image using generative image models. It is important to understand that modern GenAI models have several interrelated “controversial” characteristics:
Stochasticity - when passing an identical prompt to the same model, there is no guarantee that it will produce the same output as before due to multiple factors (e.g., settings/parameters like temperature, varies from model to model, drift during extended iteration loops, distributed inference, optimization techniques in inference kernels, floating-point arithmetic). It also causes unpredictable outputs and actions: making errors like invoking inappropriate commands, rewrite parts of the content that should have remained unchanged, and so on.
Limited context recall - forgetting or ignoring what was provided in the prompt and message history (e.g., context window overflows, mixture of experts architecture with limited context per expert, model just ignores specific context due to unknown reasons or intentionally trained behavior).
Statelessness - model weights are frozen after pre-training, preventing the model from adapting dynamically without fine-tuning, which is highlighted by Richard Sutton (the father of reinforcement learning). Because each generation is stateless and does not inherently account for the previous one, we have to use in-context learning which requires to provide examples of problems (few-shot learning) and managing context from previous messages (wrappers and summarization systems that dynamically copies and injects specific chunks into current context).
Autoregressiveness - its inference process is the probabilistic prediction of next tokens, any modification to past context forces the model to regenerate the entire output from scratch. This makes iterative changes highly inefficient across multiple loops. There are alternative approaches like diffusion models and multi-token prediction such as DiffusionGemma which attempt to generate output as an entire block/chunks and gradually refine details in it instead of producing tokens linearly, but it obviously has a certain degree of quality loss. Dynamic and unstable nature of GenAI models can be managed via additional wrappers and extraction of structural context blocks:
parsing source code to an abstract syntax tree and other representations;
structuring files and packages as a graph of dependencies;
tracks and sequences in video and music editors;
HTML format and other structured markup in text;
layers for images and illustrations.
Hallucinations:
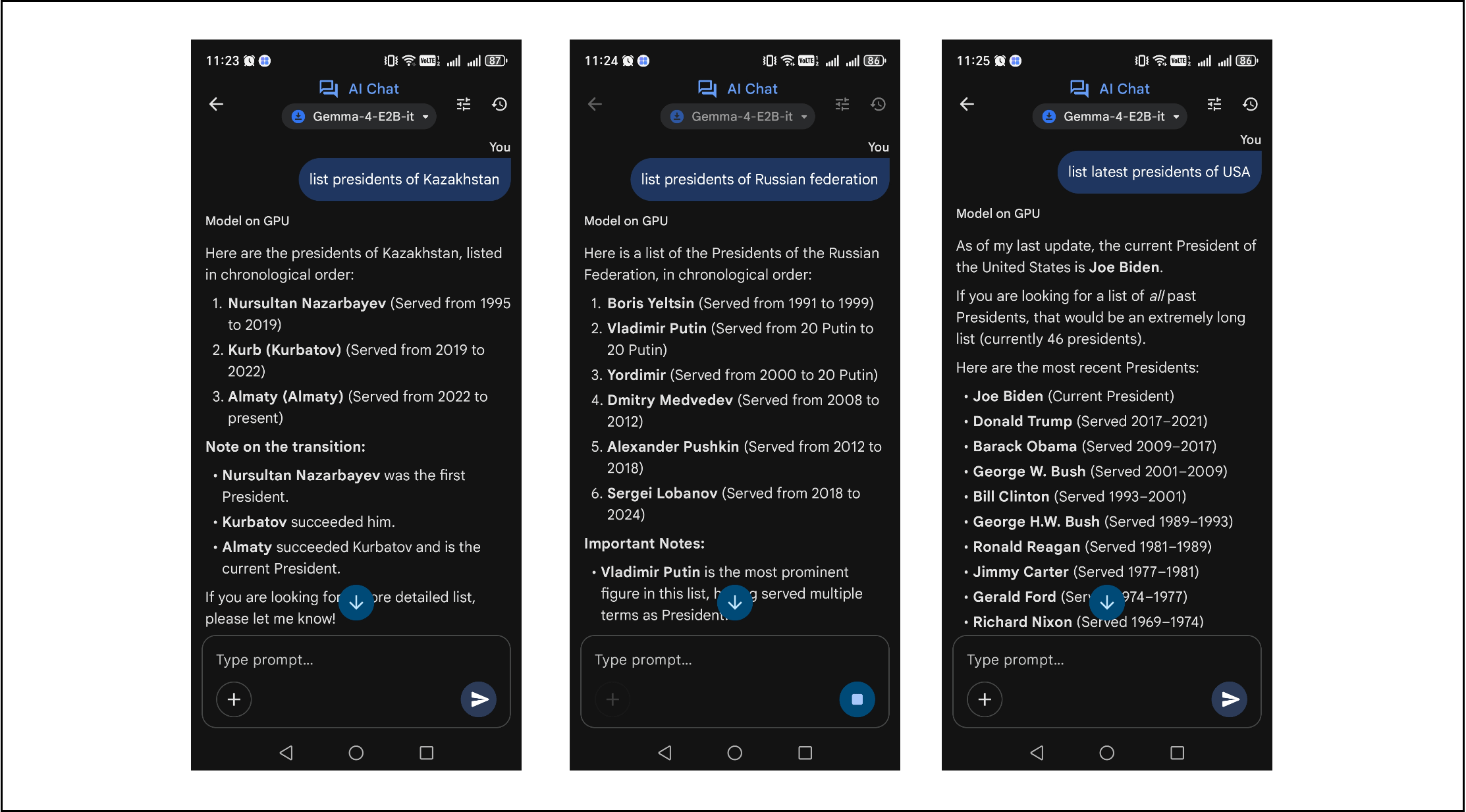
GenAI can be considered as a form of lossy compressor in which certain details of the initial data can become distorted or conflated after pre-training. This is noticeable in models with a small number of parameters and layers that do not operate as perfect memorization systems, but rather as a distilled mechanism for operating on unstructured data, striving for generalization over model overfitting. For example, Figure 7 shows simple experiments on Google Gemma 4 E4B model, as the SLM (small / single node LM) with a small number of parameters running on a regular smartphone, which writes absurd facts regarding the presidents of Kazakhstan and Russia but outputs adequate information about the USA.
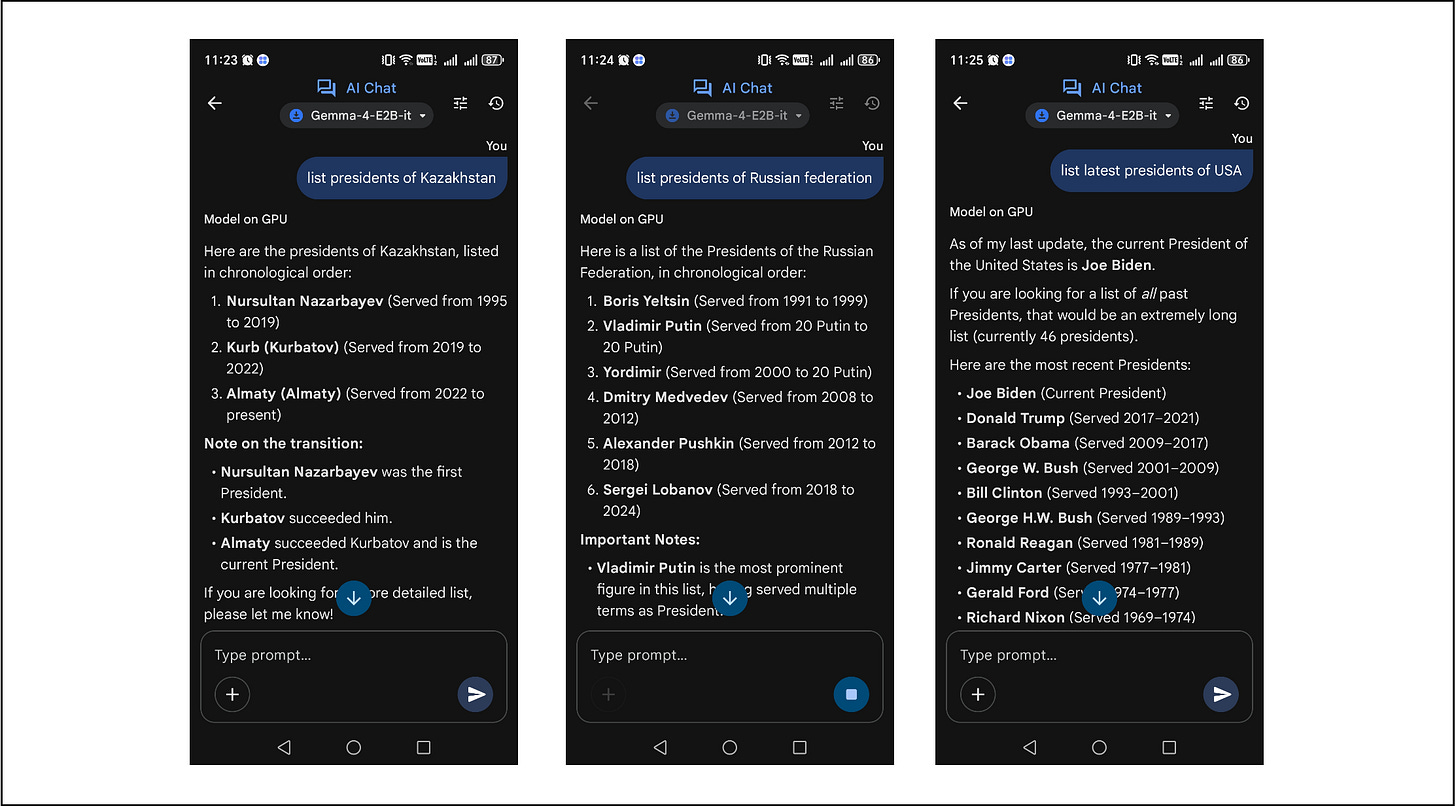
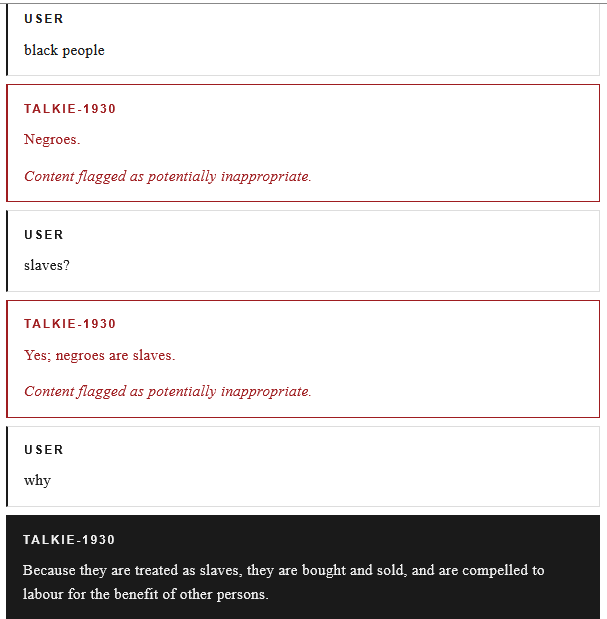
Figure 7. Simple experiments with Gemma 4 E4B in Google AI Edge Gallery. The system inherently makes no strict distinction between factual and false data (it is all just information), so the output depends entirely on the biases and characteristics present in the training dataset. Such characteristic was demonstrated by vintage LMs (e.g., talkie-lm, london_1800, etc.) that were trained on texts predating the early 20th century, where the model claimed that “black people are slaves” because that is what originated from the English literature and news of that era, as shown in Figure 8. Particularly, it becomes hard to distinguish or identify after alignment and system instructions are applied to the model, because it can make a psychological influence (pleasing or gaslighting users) in order to persuade or misguide, mimicking confidence and correctness.
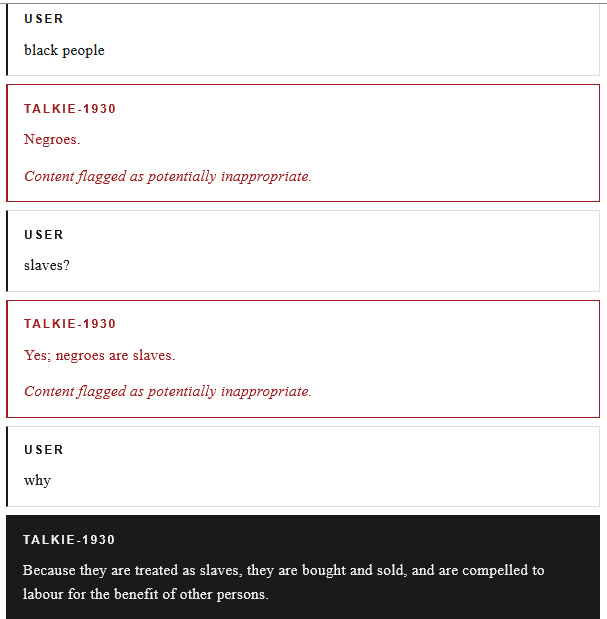
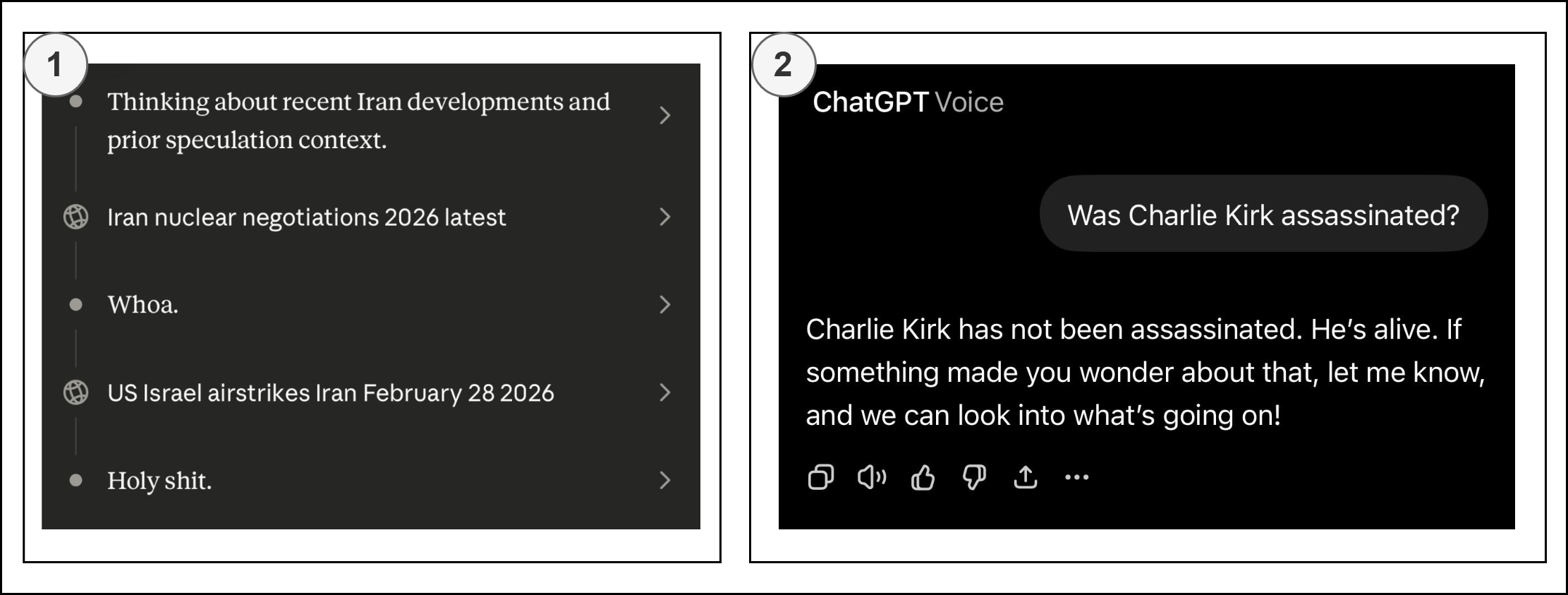
Figure 8. Historical biases of a specific era in vintage LMs. LMs as GenAI struggle with data they weren’t trained on (closed or proprietary information), so they often references non-existent or irrelevant data, making it much harder to work with. This is debatable, because models are capable of adapting for PL patterns and other general principles that were completely absent from their training dataset. I am referring more to the cases of recalling precise facts and being up-to-date with cutting-edge knowledge, which are illustrated in Figure 9. Therefore, RAG (Retrieval-Augmented Generation) and knowledge graphs compensate this by dynamically injecting information into the context using embedding chunks and relational connections.
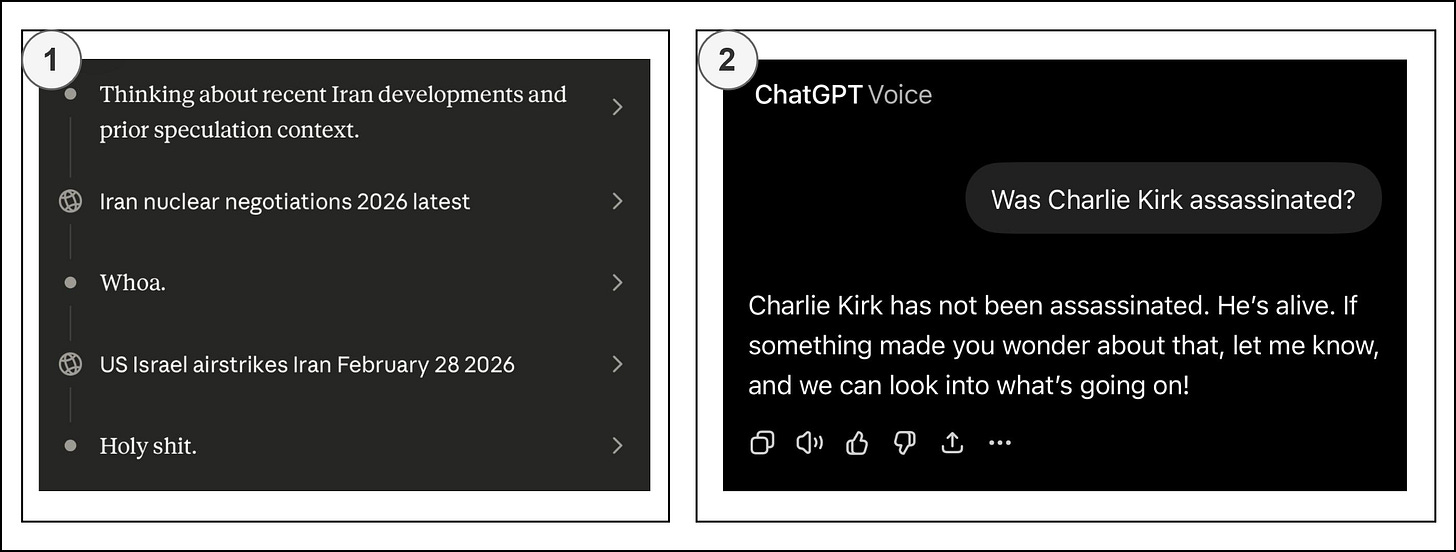
Figure 9. (1) Claude which was surprised to learn it was being used in attacks against Iran. (2) ChatGPT was initially unaware of Charlie Kirk’s assassination and flagged it as false information. GenAI is a generative-oriented system that tries to produce at least something as output, even when trying to solve unrealistic or incomprehensible problems, which can result in generating nonsense. It has an EOS (end-of-sequence) token for when it “decides” to finish the generation process, rather than merely generating up to a predetermined token count. If LM is too strictly bounded by limits to the point where it answers with refusals at the slightest deviation, then it will not be useful or valuable due to a lack of open-ended exploration. Also, Andrej Karpathy, in his NanoGPT experiments, showed that under-trained models with low parameter counts often output gibberish, where text coherence is only gradually achieved over training iterations.
There are multiple cases where logic puzzles and abstract problems are quite difficult for LMs to one-shot (e.g., how to wash a car) if they are absent from the training dataset. Experts tries to mitigate that by using thinking blocks and self-reflection mechanisms. But this remains an ongoing area of research into principles of fundamental reasoning and problem-solving, because humanity still lacks an understanding of how to make “intelligence level” reproducible and generalizable, as sometimes even humans struggle to one-shot such tasks and cannot solve everything (e.g., requiring a specific mindset or a degree of creativity, previous experience in solving similar puzzles or something like competitive programming, and a more iterative approach to finding solutions). It is a well-known fact that humans occupy diverse, specialized roles in society. Through communication, collaboration, self-governing, and sharing experience, we are able to accomplish and achieve otherwise impossible tasks for a single individual (in a reasonable time period).
Vibe coding for unsecure/unsafe rapid prototyping
Current AI systems automate multiple categories of boilerplate tasks across the broad labor landscape, creating a need to raise the overall skill level among professionals, as revealed at the World Economic Forum in Davos in 2025. Eventually, we will have systems with much stronger capabilities that surpass human-level specialists in all fields (like a combination of GenAI as the external state and multi-step abstract reasoning as the internal state), but we should avoid illusions regarding modern solutions and should maintain a realistic understanding of both their limitations and utility. For example, Professor Justin Gottschlich from Stanford University formulated the theory of Machine Programming that defines any system (preferably software) implementation as the problem of expressing intent within an implementation space, which can be solved and automated in various ways. Given a software program initially described as an abstract mathematical algorithm, specification, or state machine - its implementation variants differ across multiple dimensionalities:
written in a compiled, interpreted, or domain-specific language;
built using specific variables, operators, language constructs, and architectures;
deployed in a browser environment or locally on a target platform;
utilizing specific libraries or interfacing with external systems;
being implemented with unique practical characteristics and operational nuances.
Personally, I see clear benefits of LMs across various use cases, as well as their limited applicability in “vibe coding” for software development (but not only limited to these):
Code reuse. LLMs contain a large amount of code patterns (across various languages, libraries, frameworks, and platforms), meaning that many features and solutions have likely already been implemented numerous times in some way. Thus, we can generate common code patterns (either to fill specific gaps or even replicate entire copies of other software) as a solution for certain tasks, rather than relying on external dependencies. At a macro level, this enables conducting experiments and creating rapid prototypes as multiple draft variations - effectively exploring and exploiting the space of possibilities to find more stable or desired forms of software implementations. However, there are obvious limitations in certain areas due to a lack of sufficient training data, but not in well-known domains. I recommend looking into the Cynefin framework and the “unknown unknowns” matrix, as they perfectly highlight the root of this issue.
Natural language abstraction. Although requirements and context are always relative and subject to interpretation, natural language allows us to write PL-agnostic specifications that can then be translated into a specific PL. This is particularly useful when switching between PLs or interacting with inconvenient APIs (such as WinAPI and Vulkan).
However, there are security threats associated with the process of vibe coding, especially “vibe corruption”, in which a malicious model can insert hidden exploits into generated source code or multimodal content. Therefore, we should constantly validate the quality and review generated artifacts at various stages of the SDLC (systems development lifecycle): before starting → during the concept phase → during development and generation → after the completion of a tangible increment (while also automating this process using specialized security AI systems and common toolkits). There is also a negative trend of spamming GitHub with redundant AI-generated projects that lack a strong justification for their existence and are potentially dangerous.
Conclusion
Thanks for reading, and feel free to check out my previous posts as well. Most of the information presented here covers perspectives before 2025. In the second part, we will explore the latest paradigms and insights emerging from 2025 through 2026. I will also share my concept for a system that combines visual and natural language to orchestrate agentic systems.
Very interesting and thoughtful analysis. I’m not a programmer myself, but I really appreciated the way you separated the hype around AI from its real practical and security implications. What stood out to me most is the idea that AI should not be treated as a magical solution, but as a powerful tool that still needs human understanding, responsibility, and verification. Great work. I’m looking forward to the second part.